jsPsychとQualtricsで調査実験をしたのですが、jsPsychの個々人のデータに欠損が生じるという問題が発生しました。なぜ問題が発生したのかや、解決策をまとめます。
psyJS Advent Calendar 2021の14日目の記事です。
目次
問題の起きた実験の概要
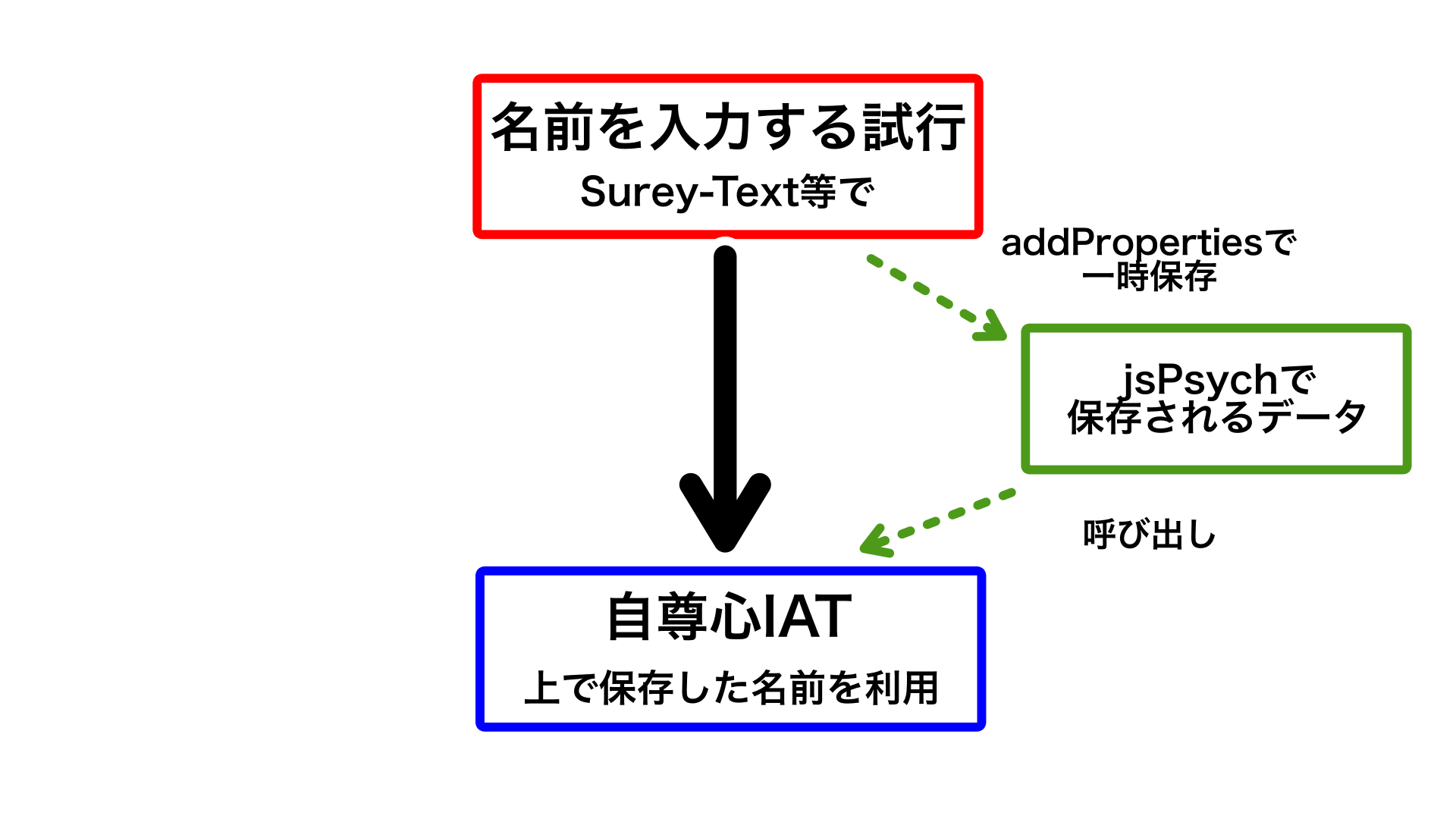
ことの発端は、この記事にあるように、参加者の姓・名を利用した自尊心IATを実施しようとしたのがきっかけでした。jsPsych上で参加者の名前をフォームで入力させ、後の自尊心IATでその姓・名をそれぞれ刺激として提示する、といった感じです(上の記事に既に対処法は記載しています)。
var name_trial= {
type: 'survey-text',
preamble:'<p>次に行う実験でどうしても必要なため記入をお願いしております。</p>'+' <p>ここで収集した名前については、次の課題でのみ使用し、分析には使用致しません。</p>'+'<p>プライバシー保護には十分配慮致します。</p>',
questions: [
{prompt: '名字(姓)を入力してください(例:田中 太郎さんなら:田中)', name: 'name_up', required:'True'},
],
button_label: '次へ',
on_finish: function(data){
//上で質問した名前を取得
nameup = jsPsych.data.get().last(1).values()[0].response.name_up;
//addPropertiesに姓・名を保存
jsPsych.data.addProperties({name01: nameup});
}
};
いろいろな実装方法がありますが、筆者は、入力してもらった姓名を”jsPsych.data.addProperties”を用い、jsPsychのデータに姓・名だけが保存される列を作成し、保存していました。
そうしてjsPsychで実装した実験を、Qualtrics上に埋め込んで、実施しました。
やらかしたこと:データが完全に記録されない
そうしてQualtricsで実験が終了し、さあ分析しよう!といった段階で、jsPsych部分のデータが上手く処理できないことに気づきます(スーッと血の気が引く)。
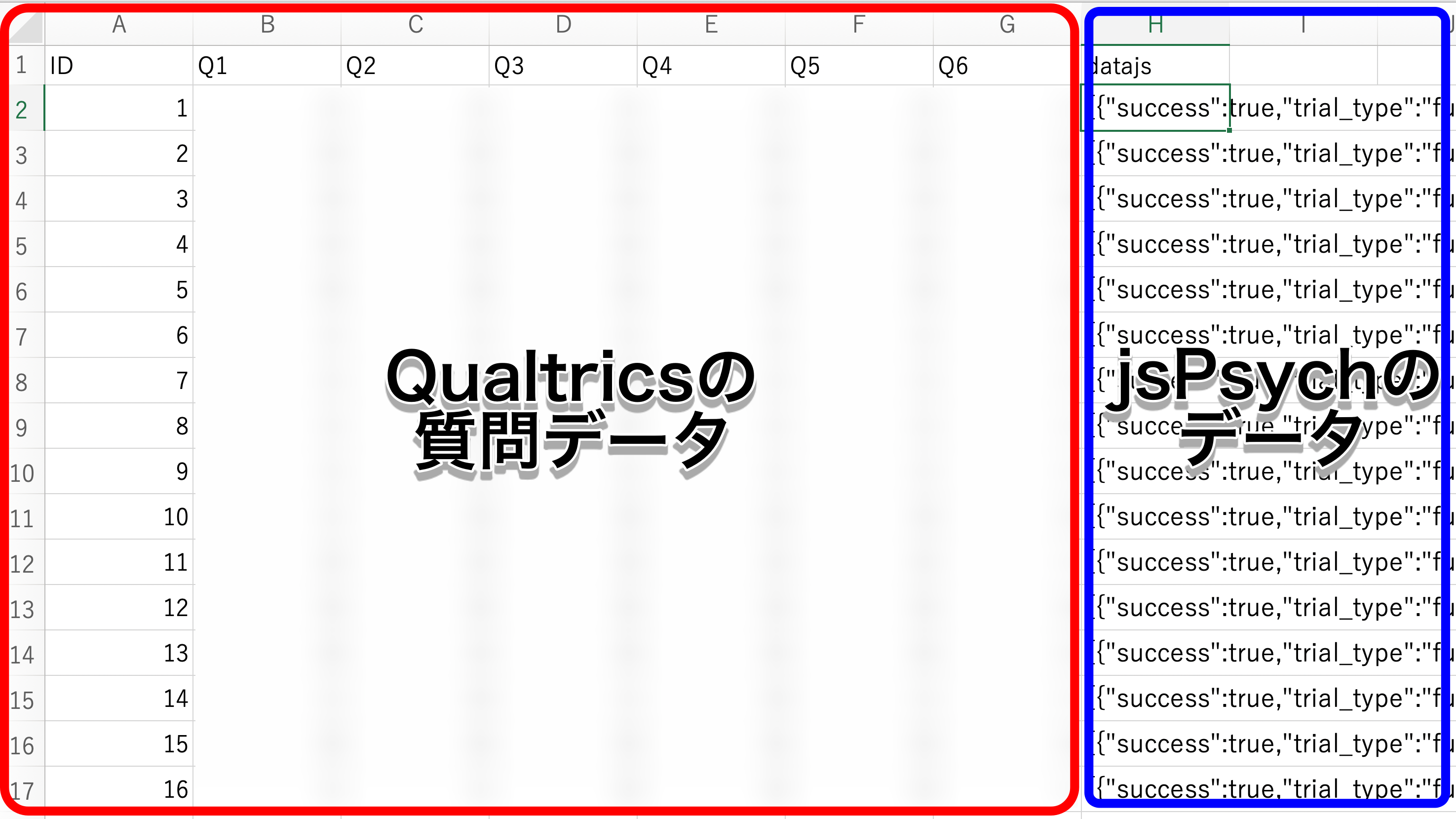
上の画像は、Qualticsでの調査と、QualtricsにjsPsychの実験を埋め込んだときのデータ例(わかりやすさのために簡略化しています)です。
QualtricsでjsPsychのデータを取得すると、個々の質問への回答と同じように、csvの1つセルの中に、個人の実験のデータがJSON形式で入ります。csvの中にJSONが入るという特殊な入れ子型になっています。通常は、Rでこのcsvを読み込み、質問紙部分とjsPsychを分離し、データの整形を行います。
jsPsychのデータ部分をRで処理しようとしたところ、データが完全に記録されていないため、処理できないという問題が発生しました。
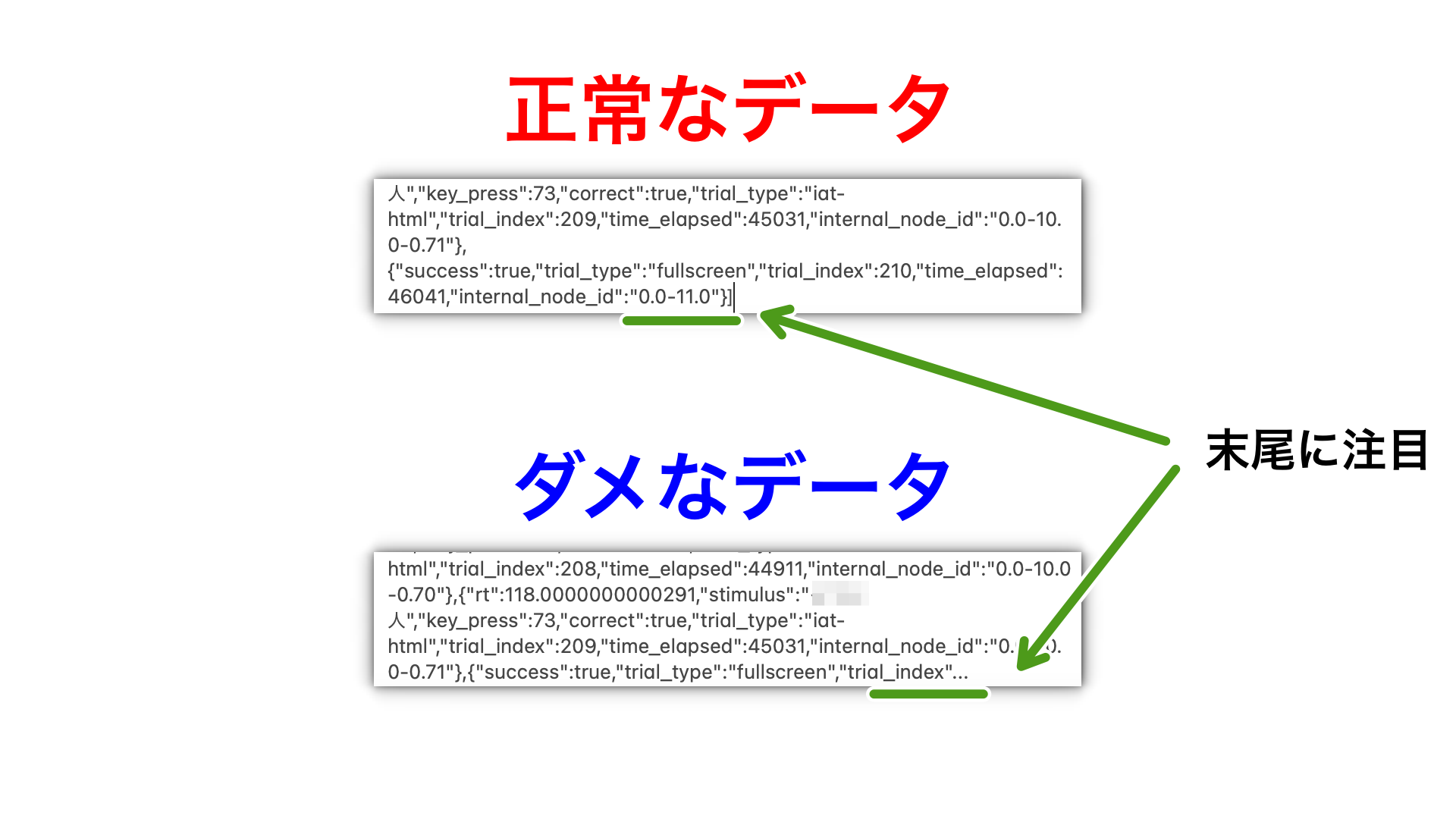
csvのセルの中にある一つのJSONデータ(上の画像は一人目)を見てみると、データが不完全な終わり方をしており、うまく記録できていないことがわかります。正常に記録できている人も少なからず存在しますが、ほとんどの人のデータが不完全な終わり方をしていました。
やらかしの原因:データ量の肥大化
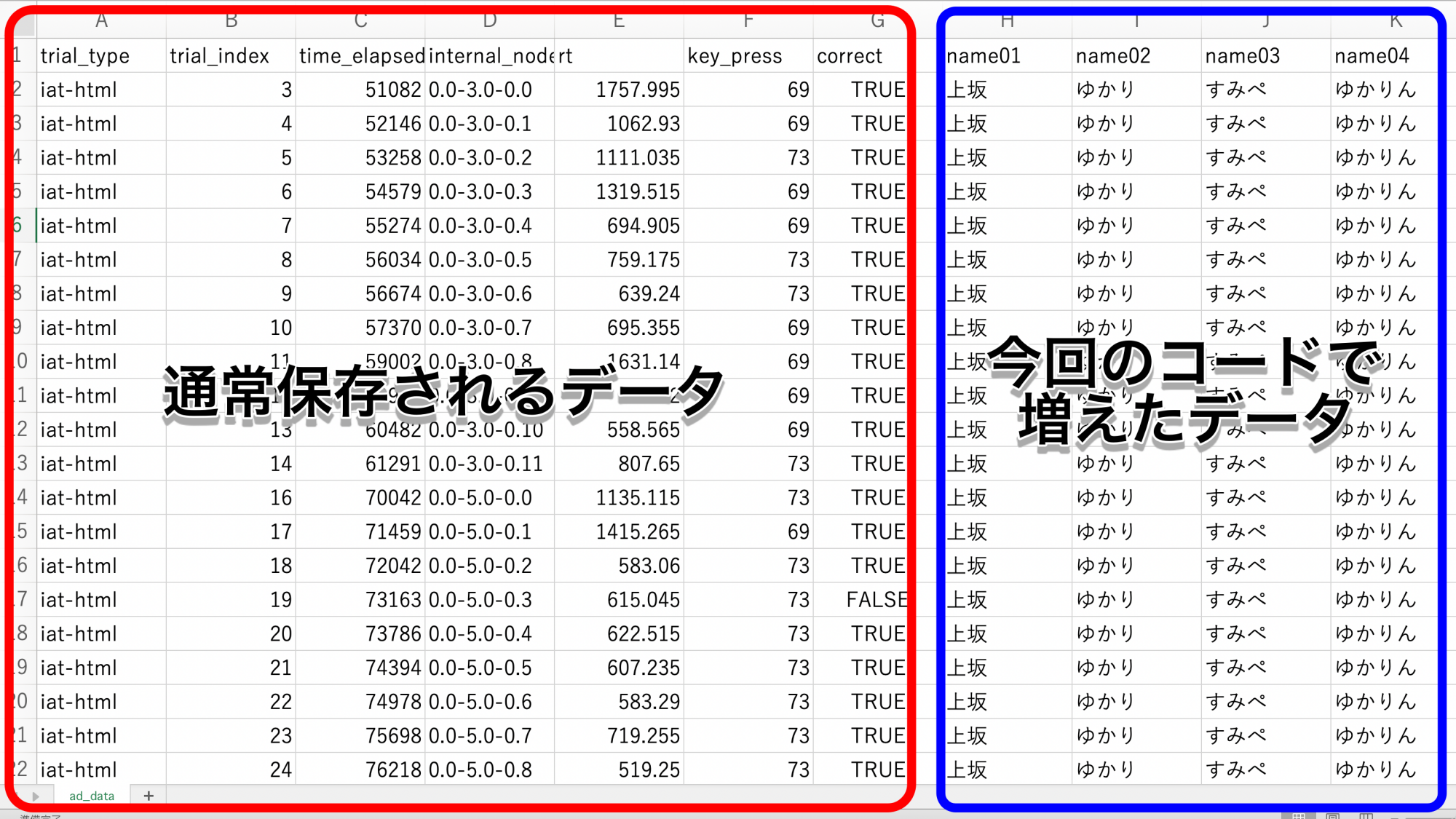
データが完全に記録されなかった理由は、addPropertiesを使用し、データが肥大化してしまったことが原因。おそらくQualtricsのデータの一つのセルに記録できるデータサイズは、50KB程度なのですが(漢字2.5万文字、半角英数5万文字)、それを超えてしまったのが原因のようです。
今回の自尊心IATでは、参加者の名前をaddPropertiesで列に保存し、後から呼び出すという形にしていました。そのため、列数や試行数が増えると、データサイズはどんどん大きくなっていきます。
例えば「上坂」という文字列を保存した場合を考えます。文字としては4バイトですが、JSON形式だと「”name01″:”上坂”」として保存されるので15バイトになります。これが200試行分毎回保存されるので、姓を保存するだけで、3KBに。これに加え、名やあだ名(「ゆかり」など)を保存すると10~15KB程度通常のデータサイズから逸脱することになります(注:実在の人物とは関係ありません)。
微々たるデータ量ですが、これによってQualtricsのセルの容量を突破してしまい、溢れ出た部分は記録されないという問題が発生してしまいました。
解決策:データのスリム化
その1:ignoreで列を消す
var datajs = jsPsych.data.get().ignore('name01').json();
実験プログラムの仕様を変更しない場合、一番簡単なのはjsPsychのオプションであるignore(‘name01’)を使って、列そのものを飛ばすという方法です。
Qualtrics上のブロック内のjsに、jsPsychの実験を読み込んだり、データを渡したりする記述をしますが、その際にデータの一時保存(姓・名)に使っていた列を消すように指定しておきます。
この指定があると、上でデータの肥大化を起こしていた”name01″列を消去することができます。複数の列を消去する際は、「.ignore(‘name01’).ignore(‘name02’)」といった風に連ねればOK。
その2:addPropertiesを使わない
2つ目は、jsPsych.data.get()メソッドを使って、明示的に名前を質問したブロックから回答データを引っ張って来て、IAT部分で利用する方法もあります。internal-node-idなどで指定する必要があったりと少々面倒くささはあります。
追記:その3
グローバルな変数に必要な情報を保存しておけば、addPropertiesもintrrnal-node-idでのデータの取り出しも必要ないと思いました。詳細を知らないので、有効ではないかもですが。 https://t.co/szQNMqpiH3
— snishiyama (@STR2480) December 14, 2021
Twitterでアドバイス頂いたのですが、予め姓名を保存するための変数をグローバルで宣言しておき、on_finish内でその変数に値を渡すことで解決しそうです。これが一番シンプルかつ良い方法かもしれません。
おまけ:もし、欠損が生じたら…
"rt":929.6899999971502,"stimulus":"清らか","key_press":69...
このような欠損が生じても、途中までのデータとして読み込む方法は、存在します(なんとか頑張った)。
大抵の場合、上記のように「,”key_press”:69…」みたいな形で、末尾が終わっています。Rのstringrパッケージを使って、一番後ろから”,”の位置を検索し、”,”key_press”:69…”を削除、末尾に”}]”を追加します。強制的にJSON形式のデータとして正常な形にすることで、欠損はありながらも、なんとか読み込めるようになります。
実施前のデータチェックとデバッグはしっかりと
今回このような問題が起きた理由としては、デバッグが不十分であったことです。
もちろん、実施前には、ちゃんとQualtricsにデータが保存されているかは確認していました。しかし、姓・名・あだ名の長い人までは考慮できておらず、今回のような問題が発生しました。
実験や調査を開始する前には、自分の想定しないサイズのデータ入力も試し、正常に記録されるか確認した上で開始するようにしましょう。