気合とRで、国会で行われた首相の所信表明演説をスクレイピングしてみたのでやり方を紹介します。
正直for文とかリストの使い方とか、うまい人がやればもっと綺麗にできるとは思いますが、一応備忘録程度にメモしておきます。
目次
APIの仕組みを理解する
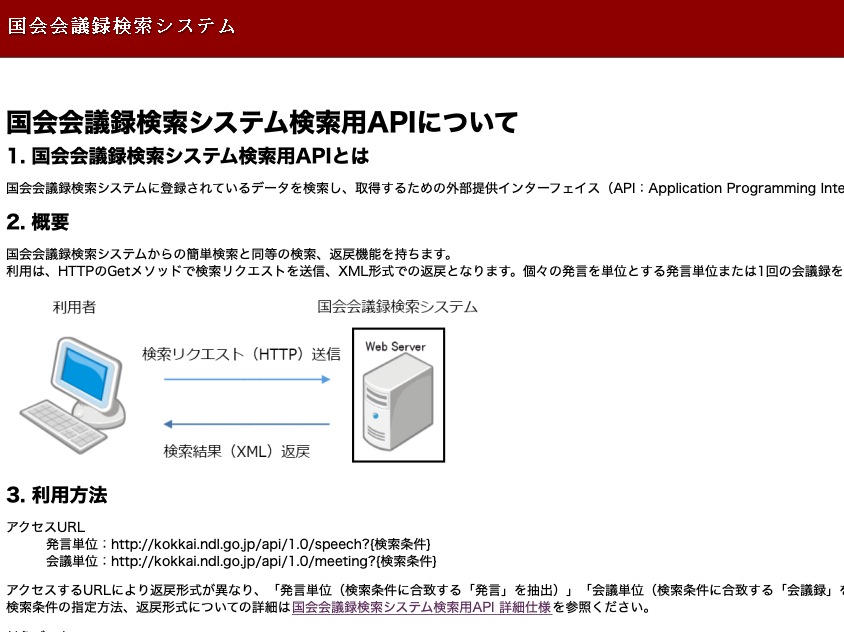
発言単位:http://kokkai.ndl.go.jp/api/1.0/speech?{検索条件}
会議単位:http://kokkai.ndl.go.jp/api/1.0/meeting?{検索条件}
APIを使うことによって発言単位や会議単位で、誰がどんな発言をしたかを抽出することができます。ちなみに検索条件を指定したあと、URLのエンコード・デコードツールを使って、日本語URLを変換する必要があります。
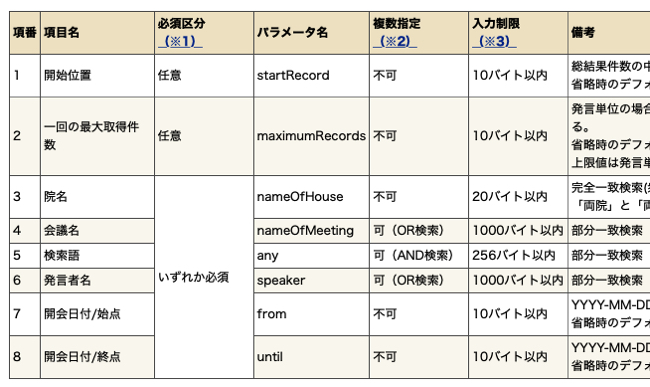
首相の所信表明演説は、nameOFMeetingに「本会議」での、anyに「所信についての演説」「所信に関する演説」をいれて、それぞれURLに反映してやればいいわけです。
#デコード前
"http://kokkai.ndl.go.jp/api/1.0/speech?nameOfMeeting%3D本会議%26any%3D所信についての演説"
#デコード後
"http%3A%2F%2Fkokkai.ndl.go.jp%2Fapi%2F1.0%2Fspeech%3FnameOfMeeting%253D%E6%9C%AC%E4%BC%9A%E8%AD%B0%2526any%253D%E6%89%80%E4%BF%A1%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6%E3%81%AE%E6%BC%94%E8%AA%AC"
#注意ポイント
"http://kokkai.ndl.go.jp/api/1.0/speech?nameOfMeeting={検索条件}&any{検索条件}"
%26: &
%3D: =
注意ポイントとしては検索条件は「=」で指定し、検索条件間は「&」で繋ぐ必要があり、エンコードしたときにこれらが上の様に変換されているのに注意しておく必要があります。最近のブラウザは優秀なので&と=がデコードされていれば、後は日本語でもうまく検索してくれるようです。
指定した通りに動かないAPI
追記:「所信についての演説」と「所信に関する演説」問題
- 臨時国会の冒頭
- 特別国会で内閣総理大臣が指名・任命された後
- 国会の会期途中で内閣総理大臣が交代した場合
「所信についての演説」と「所信に関する演説」の二種類があるので、検索する際には注意しないといけません。特にこれは最近でも混在しているので注意。
期間を区切る必要あり
"http://kokkai.ndl.go.jp/api/1.0/speech?nameOfMeeting%3D本会議%26any%3D所信についての演説"
例えば上記の様に指定した場合、「所信についての演説」をすべて抜き出してくれるのかと思いきや、たったの25年分。スクレイピングする際は期間指定を5年から10年ごとに区切るにする必要があります。
speech or meeting問題
発言単位:http://kokkai.ndl.go.jp/api/1.0/speech?{検索条件}
会議単位:http://kokkai.ndl.go.jp/api/1.0/meeting?{検索条件}
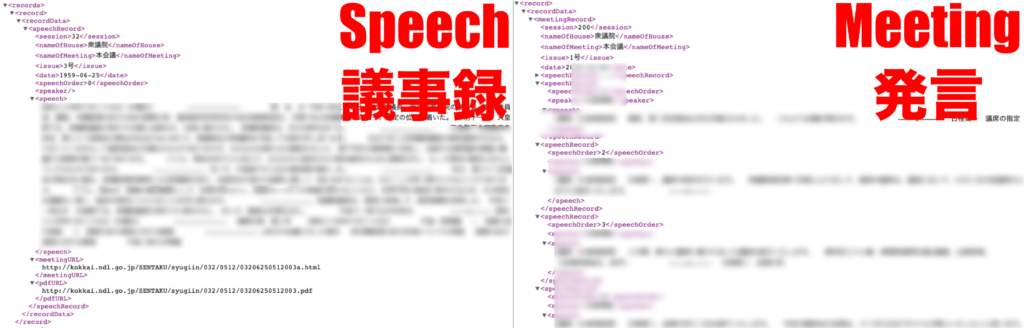
もう一つの問題は、リンクに”speech”を使うか”meeting”を使うかという問題。
speechを使うと数回分の議事録の目次が取得できます。あくまで目次。meetingを使うと会議内での発言をそのまま取得できますが、一回あたり2会議分程度。発言はすべて

そこで解決策として目をつけたのが”speech”を使う際に取得できる”
“meeting”でも取得できますが、”speech”の方が安定して複数年取得しやすいのでこちらを使用することにしました。
スクレイピングをする
リンクリストを作る

まず、リンクの作成規則に従って、「本会議」「所信についての演説」を含む10年ごとのリンクを作成します。今回は戦後に絞って期間指定は「1940-01-01~1945-01-01」「1945-01-01~1950-01-01」…という風にリンクを作成しcsvファイルとして保存しました。Rでリストを作ってもいいと思います。
meetingURLの取得
# 所信URLから演説テキストのリストを作る ----------------------------------------------------------------
#"sn"は所信についての演説
url_list01 <- read.csv("data/snurl_list.csv", header = FALSE)
url_list01 <- as.data.frame(url_list01)
#"sk"は所信に関する演説
url_list02 <- read.csv("data/skurl_list.csv", header = FALSE)
url_list02 <- as.data.frame(url_list02)
“snurl_list.csv”と”skurl_list.csv”に、naomeOFMeetingに「本会議」、anyに「所信に関する演説」又は「所信についての演説」、fromとuntilで「from=1940-01-01&until=1950-01-01」のように10年ごとに年限を区切ったリンクのリストをExcelで作ります。
#最終的にmedia1にすべての演説のリンクが入る様にしている
#media1_01に所信についての演説のリスト
for(i in 1:6){
if(i == 1){
url <- url_list01[[1]][i]
url <- as.character(url)
url_data <- read_xml(url)
media1_01 <- html_nodes(url_data,"meetingURL") %>%
html_text()
media1_01 <- as.list(media1_01)
remove(url_data, url)
}else{
url <- url_list01[[1]][i]
url <- as.character(url)
url_data <- read_xml(url)
media2 <- html_nodes(url_data,"meetingURL") %>%
html_text()
media2 <- as.list(media2)
media1_01 <- union(media1_01, media2)
remove(url_data, media2, url)
}
}
#media1_02に所信に関するの演説のリスト
for(i in 1:6){
if(i == 1){
url <- url_list02[[1]][i]
url <- as.character(url)
url_data <- read_xml(url)
media1_02 <- html_nodes(url_data,"meetingURL") %>%
html_text()
media1_02 <- as.list(media1_02)
remove(url_data, url)
}else{
url <- url_list02[[1]][i]
url <- as.character(url)
url_data <- read_xml(url)
media2 <- html_nodes(url_data,"meetingURL") %>%
html_text()
media2 <- as.list(media2)
media1_02 <- union(media1_02, media2)
remove(url_data, media2, url)
}
}
#media1_01とmedia1_02のリストを結合、並べ替え
speech_list <- union(media1_01, media1_02)
for文とhtml_nodesを使って、最終的には”media1_01″と”media1_02″というリストに、それぞれ1940年以降の「所信についての演説」「所信に関する演説」があった会議のリンクを取得しています。
#"a.html"を"c.html"に置き換える
speech_list <- gsub("a.html", "c.html", speech_list)
speech_list <- c(speech_list)
speech_list <- as.data.frame(speech_list)
speech_list <- speech_list[order(speech_list$speech_list),]
speech_list <- as.data.frame(for文とhtml_nodesを使って、最終的には"media1_01"と"media1_02"というリストに、それぞれ1940年以降の「所信についての演説」「所信に関する演説」があった会議のリンクを取得しています。)
ちなみに”meetingURL”は末尾が”a.html”で終わりますが、これだとヘッダー部分だけなので本文を取得するために”c.html”にリンクを置き換えています。
あとは国会の回数順にリンクを並べ替えspeech_listに保存しています。
# テキストデータ取得 ---------------------------------------------------------------
speech_list <- as.data.frame(speech_list)
for(i in 1:59){
if(i == 1){
speech_url <- speech_list[[1]][i]
speech_url <- as.character(speech_url)
speech_rh <- read_html(speech_url, encoding = "CP932")
media2_1 <- html_nodes(speech_rh, "body") %>%
html_text()
remove(speech_rh, speech_url)
}else{
speech_url <- speech_list[[1]][i]
speech_url <- as.character(speech_url)
speech_rh <- read_html(speech_url, encoding = "CP932")
media2_2 <- html_nodes(speech_rh, "body") %>%
html_text()
media2_1 <- union(media2_1, media2_2)
remove(speech_rh, media2_2, speech_url)
}
}
上で作成したmeetingURLが入ったリストを元にfor文を回して、”media2_1″というリストに発言内容が入るようにしています。
発言内容から首相の発言を抽出する
第200回国会 本会議 第1号
令和元年十月四日(金曜日)
―――――――――――――
“meetingURL”のリンクにアクセスしてもらえればわかると思いますが、抜き出した発言内容の中には、第何回の国会であるとか日付とか、議事進行の目次とか、議長とか議員さんの発言、細かな「拍手」まで含まれており、ここから首相の所信表明演説を抜き出す必要があります。
- 首相演説が「○内閣総理大臣(」という文字列から始まるので、その前に何文字あるか、各ページごとにカウントしてリストを作成。
- リストを元にfor文でカウントした数字ごと、各ページから頭から削除
- 首相演説の終わりが「(拍手)\n—–◇」(古いものは(拍手)○議長” or “――――◇―――――○議長“)がどの位置にあるか確認・リスト作成。
- for文で末尾削除
そこで僕のとった方法はこれ。首相演説は「○内閣総理大臣(」という文字列でスタートするので、それが何文字目かを検索。ちなみに戦後数年は「○国務大臣(」でスタートします。その何文字目かを元に、頭から文字をカット。後ろも基本的には「(拍手)\n—–◇」で終わるので何文字目かを取得、うしろから文字をカットします。
# 何文字目から内閣総理大臣という文字が始まるか確認 ------------------------------------------------
#31行目は「○内目総理大臣」
naisou_list <- str_locate(speech_raw[,1], "○内閣総理大臣")
naisou_list <- as.data.frame(naisou_list)
str_locate(speech_raw[, 1], "○内目総理大臣")
naisou_list[46, ] <- c(285, 291)
kokumu_list <- str_locate(speech_raw[, 1], "○国務大臣")
for(i in 1:14){
sr <- i
naisou_list[sr, ] <- kokumu_list[sr, ]
}
各回によって何文字目から首相発言が始まるかは異なるので、そのリストを作ります(”naisou_list”)。ちなみに「○内目総理大臣」の回が存在します。1〜14行目は「○国務大臣」です。
# 「○内閣総理大臣」より前の文字を消去 ------------------------------------------------------
for(i in 1:nrow(speech_raw)){
if(i == 1){
sr <- i
start_num <- naisou_list[sr, 1]
speech_m1 <- str_sub(speech_raw[sr, ], start_num, 50000)
}else{
sr <- i
start_num <- naisou_list[sr, 1]
speech_m2 <- str_sub(speech_raw[sr, ], start_num, 50000)
speech_m1 <- rbind(as.list(speech_m1), as.list(speech_m2))
}
}
「○内閣総理大臣」より前の文字を消去しています。
# 文字の置換 ----------------------------------------------------------------
speech_m1 <- gsub(" ", "", speech_m1, fixed = TRUE)
speech_m1 <- gsub(" ", "", speech_m1, fixed = TRUE)
speech_m1 <- gsub("────", "――――", speech_m1, fixed = TRUE)
df_speech_m1 <- as.data.frame(speech_m1)
# 下の文字列カット ----------------------------------------------------------------
end_list <- str_locate(speech_m1, "(拍手)\n――――")
end_list <- as.data.frame(end_list)
# #3, 4, 7がない
end_bou_list <- str_locate(speech_m1, "(拍手)○議長")
end_bou_list <- as.data.frame(end_bou_list)
end_list[1, ] <- end_bou_list[1,]
end_list[2, ] <- end_bou_list[2,]
end_list[3, ] <- end_bou_list[3,]
end_list[4, ] <- end_bou_list[4,]
end_list[5, ] <- end_bou_list[5,]
end_list[6, ] <- end_bou_list[6,]
# # 57
end_boug_list <- str_locate(speech_m1, "――――")
end_boug_list <- as.data.frame(end_boug_list)
end_list[7, ] <- end_boug_list[7,]
for(i in 1:nrow(df_speech_m1)){
if(i == 1){
sr <- i
end_num <- end_list[sr, 1]
speech_m3 <- str_sub(df_speech_m1[sr, ], 1, end_num)
}else{
sr <- i
end_num <- end_list[sr, 1]
speech_m4 <- str_sub(df_speech_m1[sr, ], 1, end_num)
speech_m3 <- rbind(as.list(speech_m3), as.list(speech_m4))
}
}
remove(speech_m3, speech_m4, speech_final)
speech_final <- gsub("\n", "", speech_m3)
speech_final <- as.data.frame(speech_final)
speech_final <- str_sub(speech_final$speech_final, 1, -2)
speech_final <- as.data.frame(speech_final)
#3,4行目に吉田内閣、鳩山内閣の答弁があるので削除
speech_final <- speech_final[-3,]
speech_final <- as.data.frame(speech_final)
speech_final <- speech_final[-3,]
speech_final <- as.data.frame(speech_final)
write.csv(speech_final, "speech_final2_cp932.csv", fileEncoding = "CP932")
先に述べた「○内閣総理大臣」より前の文字を消去の同様、終わりに合わせて削除しています。1~6回、7回は所信表明演説の終わり方が違うのでその分を分けています。
○内閣総理大臣(hogehoge君){発言内容}
○内閣総理大臣(hogehoge2君){発言内容}
○内閣総理大臣(hogehoge3君){発言内容}
.
.
.
の様なリストができているはず。勿論gsub関数を使って「)君」までの文字数をカウントして削除すれば、余計なものは消えますし、誰の発言かを合わせたリストも作成することが可能だと思います。stringrパッケージの”str_split_fixed”を使えばもっと簡単にできるかもしれません。
Source:国会会議録検索システム