Qualtricsで調査したデータ(csv)をRで読み込もうとすると、余計な行が入っていたり、全て文字列型で読み込まれてしまったりと面倒なことが多々あります。
読み込む前に、ExcelやNumbersなどで前処理をしたcsvを作成せずに、Qualtricsからダウンロードしたcsvをダイレクトに読み込む方法を紹介します。
問題:Qualtricsのcsvに余計なものが多い
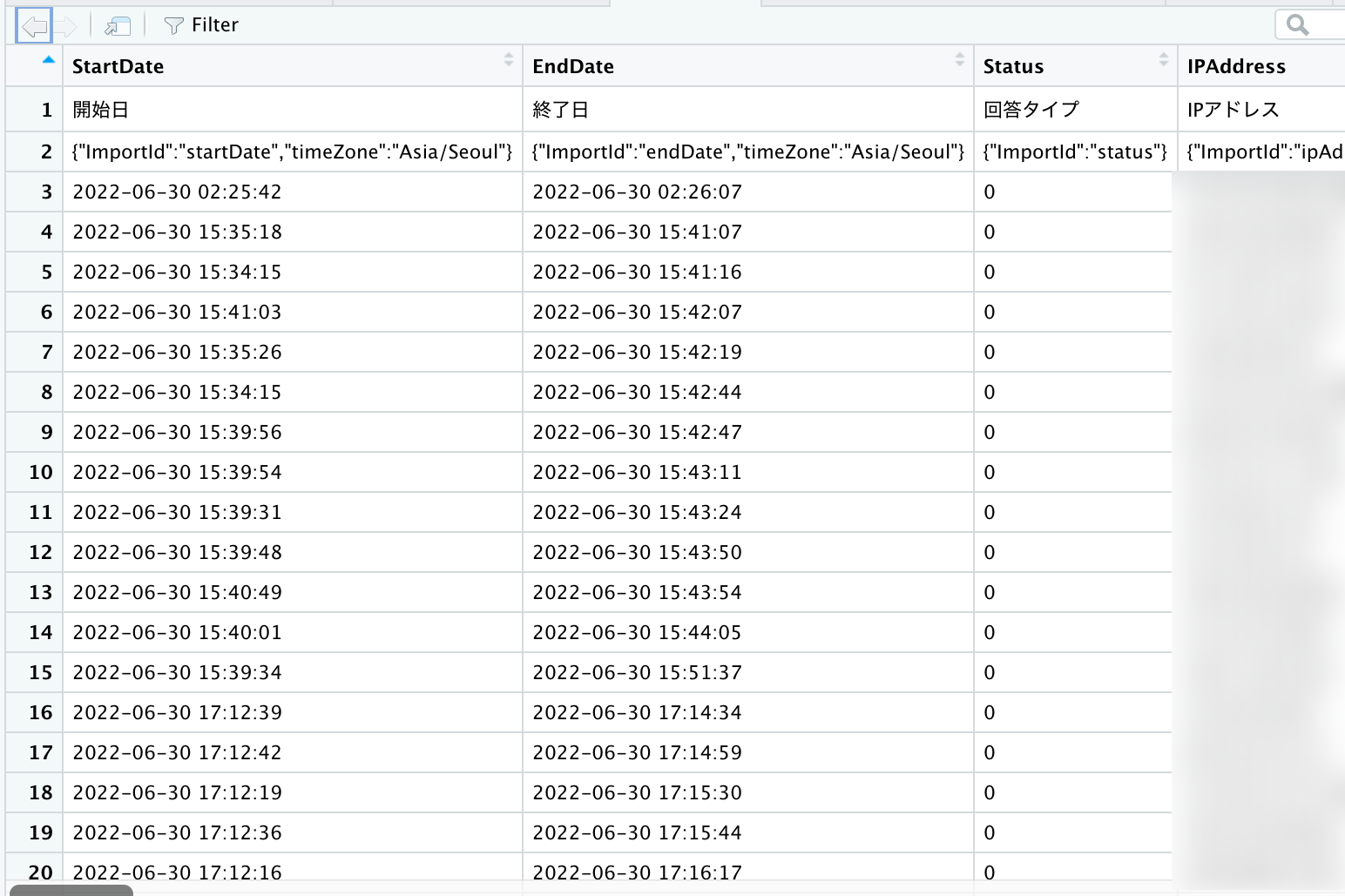
Qualtricsで作成したcsvを、read.csv関数で読み込むと、上記のような形になります。列名が英語と日本語で重複していたり、”{{ImportID….}}”が入っていたりと、ダイレクトに読み込むといろいろおかしな形になります。

さらに、日本語の列名行があることで、全て文字列型で読み込まれてします。
解決策:行をスキップする。
all_content <- readLines("data/hogehoge.csv")
skip_second <- all_content[-c(2:8)]
dat_q2_temp <- read.csv(textConnection(skip_second), header = TRUE, stringsAsFactors = FALSE)
1行目のreadLines関数を使って、csvの各列をすべて読み込みます。
2行目のskip_secondの所では、読み込みをスキップしたい列をall_contentから除外します。筆者の手元のデータでは、2~8行目は、データとは関係のない列だったので削除しました(不要な行は、データによって変わると思います。all_content[8]などと実行しながら、不要な列がどこまでかをチェックしましょう)。
3行目は、textConnectionでskip_secondまとめて、read.csv関数で読み込んでいます。
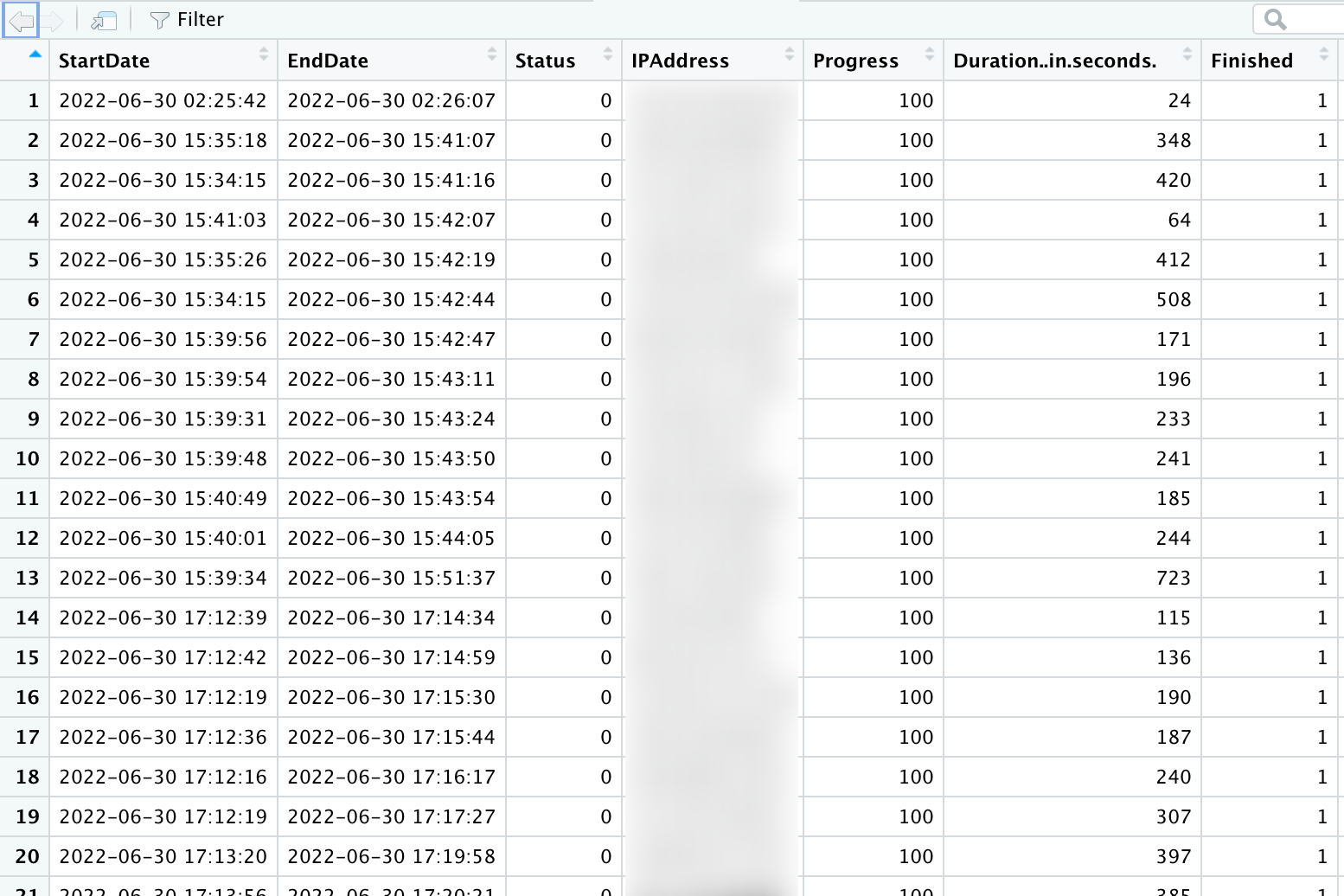
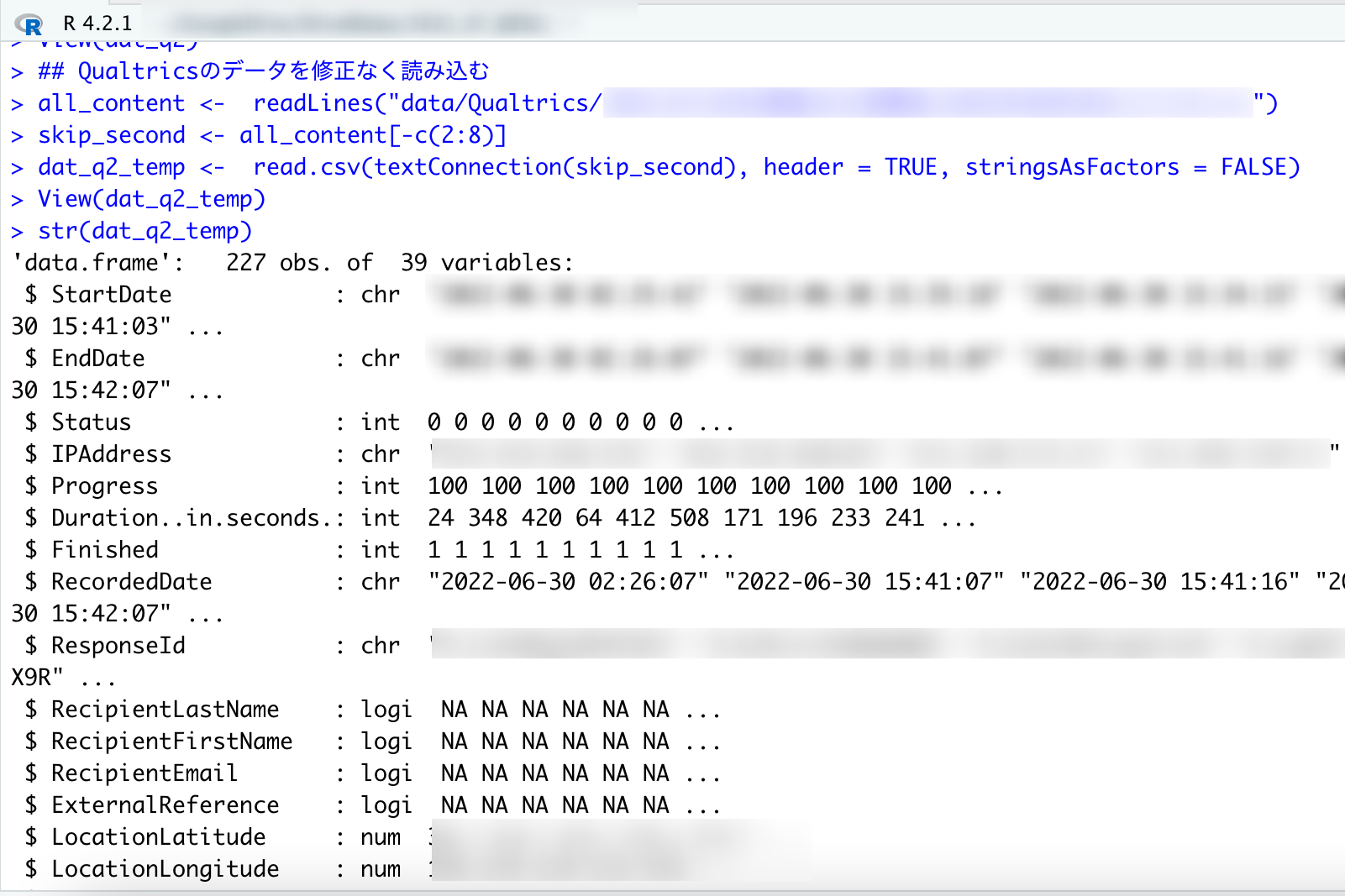
これで綺麗にデータを読み込むことができるようになりました。余計な行はなく、データについても文字列は文字列型、数字はint型になっています。
参考リンク

I have a CSV file with two header rows, the first row I want to be the header, b…
stackoverflow.com