
RStanで推定したパラメータの推定値を、他の分析などに利用したいなんてことがありますよね。特に階層モデルを用いた場合、個人ごとの推定値が算出され、行数で指定して抜き出すことは非常に面倒になります。行数のカウントをミスするとデータの取り違えにもになります。
行名で抽出する方法の紹介です。
行数指定の場合
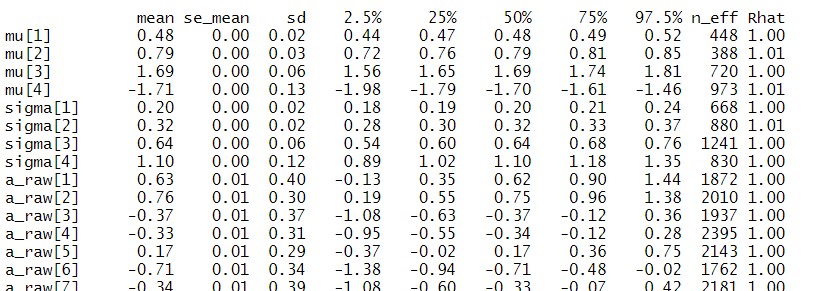
上の様な推定結果が”fit”というオブジェクトに格納されており、a_raw[1]~a_raw[150]までのパラメータを抽出したいとします。
# result_meanにfitの中のmeanを格納 result_mean <- summary(fit)$summary[, "mean"] result_mean <- as.data.frame(result_mean) mean_a <- result_mean [9:158,]
Stanの推定結果は、”S4オブジェクト”なる複雑な形式で保存されているらしい。(一番最後の北條さんのスライドを参照)。推定結果から抜き出したい場合はsummary(hogehoge)$summary[, 抜き出す列名]で。
あとはデータフレームに変換して、行数を指定してあげると、抽出が可能に。ただこれは、一つでもズレるとミスになってしまう問題が存在します。
行名で抜き出す方法
# result_meanにfitの中のmeanを格納
result_mean <- summary(fit)$summary[, "mean"]
result_mean <- as.data.frame(result_mean)
#ここからが違う。空のリストを作成し、それに入力していく形に。
mean_a<- list()
for(i in 1:150){
name_a <- paste("a_raw[", i, "]", sep = "")
mean_a$a_raw[i] <- result_mean [name_a ,]
remove(name_a)
}
最初、推定値を抜き出すところは行数指定と全く同じ。
for文の”i”は文字列内に使用できないので、行名をresult_mean ["a_raw[i]",]の様な形で、a_rawを変更して抽出することはできません。
そこで、paste関数を用いて数字と文字列を足し算し、それを改めてresult_mean [hogehoge,]に代入することで、for文を使って抽出できるようにしました。ここで最後にできるmean_aはリストになっているので、as.data.frame()を使って変換すれば、データフレームとして利用できます。
もし何かもっと良い方法があれば、教えて下さい。
Stanの便利な事後処理関数 from daiki hojo